
동시성 제어; 비관적 락을 통해 요청에 대한 데이터 정확성 확보
💡 참고:
동시성 제어(Concurrency Control)란?
다중 사용자 환경을 지원하는 데이터베이스 시스템에서는, 여러 트랜잭션1들이 동시에 실행되기 마련이다. 이 때, 트랜잭션 간의 간섭으로 인한 문제가 발생하지 않도록, 트랜잭션의 실행 순서를 제어하는 것을 말한다.
문제 상황
여러 사용자가 동시에 구매 요청을 보냈을 때, 구매 처리된 상품 개수와 남은 상품 개수 간 데이터 불일치 문제가 발생했다. (테스트는 JUnit으로 진행했다.)
➡️ 테스트 조건: 사용자 1,000명이 100개의 상품에 대해 동시에 구매 요청
1. 구매 처리된 상품 개수
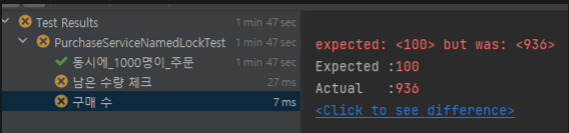
expected: <100> but was: <936>
Expected : 100
Actual : 936
DB에 있던 전체 상품 수량은 100개였다. 하지만, 테스트 결과 상품 수량을 훨씬 웃도는 936개의 상품이 구매 처리되었다.
2. 남은 상품 개수
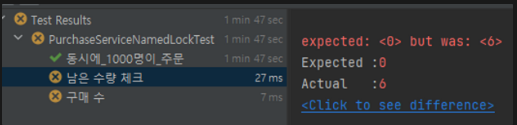
expected: <0> but was: <6>
Expected : 0
Actual : 6
반면, 남은 상품 개수는 오히려 6개가 남아있었음을 확인할 수 있었다. 정상적으로 구매된 것은 94개라는 의미이다. 이런 현상이 실제 서비스에서 일어났다면, 큰 혼란을 야기했을 것이다.
테스트 결과, 구매 처리된 상품 개수와 현재 남은 상품 개수의 데이터의 정확성이 확보가 되지 않고 있음을 알 수 있다. 이러한 문제를 해결하기 위해, 동시성 제어 기법을 도입하기로 결정했다.
비관적 락(Pessimistic Lock)이란?
하나의 트랜잭션이 데이터에 접근하면, 데이터를 잠구어 다른 트랜잭션이 해당 데이터를 수정하거나 삭제하는 것을 방지한다. 데이터 동시 접근에 대해 비관적인 시나리오를 가정(충돌이 발생할 것으로 예상)하여, 이를 방지하기 위한 방법이기 때문에, ‘비관적 락’이라고 부른다. 잠금(Lock)은 데이터에 접근한 트랜잭션이 완료될 때까지 유지된다.
비관적 락 도입의 이유
당시 도입하려던 동시성 제어 기법 후보에는 동기화(Synchronized), 비관적 락(Pessimistic Lock), 낙관적 락(Optimistic Lock), 네임드 락(Named Lock)이 있었다.
1. 낙관적 락(Optimistic Lock):
비관적 락은 대기 시간이 필연적으로 발생하기 때문에, 동시에 발생하는 트랜잭션이 많을수록, 성능이 저하될 수 있다는 단점이 있다. 이 때문에 비관적 락과 대조적인 낙관적 락(Optimistic Lock) 방식을 사용하는 경우도 많다.
낙관적 락은 잠금을 걸지 않고, 트랜잭션이 종료될 때 변경 충돌이 발생했는지 확인하고, 충돌이 발생했다면, 트랜잭션을 롤백하거나 재시도하는 방식이다. 주로 버전 관리 등을 활용해서 데이터를 변경 여부를 비교한다. 비관적 락보다는 속도가 빠르지만, 데이터 충돌이 자주 발생하는 시스템에서는 부적절하다.
이번 프로젝트에서는 집중되는 트래픽이 많아, 충돌이 빈번히 발생하기 때문에 낙관적 락 도입은 부적절하다고 판단했다.
2. 동기화(Syncronized):
Syncronized는 Java에서 지원하는 키워드로, 현재 데이터를 사용하고 있는 해당 스레드를 제외하고, 나머지 스레드들은 데이터 접근을 막아, 순차적으로 데이터에 접근할 수 있도록 해준다. 하지만 하나의 프로세스 안에서만 보장이 된다는 단점이 있다. (즉, 서버가 2대 이상일 경우에는 데이터에 대한 접근을 막을 수 없다.)
3. 네임드 락(Named Lock):
테이블이나 레코드, 데이터베이스 객체가 아닌, 사용자가 지정한 문자열에 대해 락(Lock)을 획득하고 반납하는 기법이다. 한 세션이 락을 획득하면, 다른 세션은 해당 세션이 락을 해제한 이후에만 획득할 수 있다. (이 때, 락은 자동으로 해제되지 않기 때문에, 획득 후에 처리가 끝났다면 명시적으로 해제해 주거나 선점시가니 끝나야 한다.)
Amazon ELB(Elastic Load Balancer) 사용으로 세션과 서버가 여러 개로 나뉘었고, 이러한 환경으로 인해 동기화와 네임드 락을 도입하는데에 어려움이 있다고 판단했다.
➡️ 비관적 락 적용
@Lock 어노테이션을 통해 비관적 락(Pessimistic Lock)을 사용할 것이라고 명시하고, @Query 어노테이션을 사용해 id 정보를 통해 item(상품)을 찾을 것이라고 직접 쿼리문을 작성해주었다.
ItemRepository.java
import org.springframework.data.jpa.repository.Lock;
import jakarta.persistence.LockModeType;
@Repository
public interface ItemRepository extends JpaRepository<Item, Long>, ItemRepositoryCustom {
@Lock(LockModeType.PESSIMISTIC_WRITE) // ←
@Query("select s from Item s where s.id=:id") // ←
Optional<Item> findByIdWithPessimisticLock(Long id);
/* ... */
}
상품 정보를 다루는 ItemServiceImpl class에서 Lock을 거는 메서드인 findItemPessimisticLock()을 작성했다. 이 메서는 구매자(사용자)가 상품을 구매할 때 호출되는 PurchaseServiceImpl.purchaseItem() 메서드 내에서 호출된다.
ItemServiceImpl.java
public Item findItemPessimisticLock(Long id) {
return itemRepository.findByIdWithPessimisticLock(id).orElseThrow(() ->
new CustomException(CustomErrorCode.ITEM_NOT_FOUND, null)
);
}
PurchaseServiceImpl.java
@Override
@Transactional
public void purchaseItem(Long itemId, PurchaseRequestDto requestDto) {
User user = userService.findUser(requestDto.getEmail());
Item item = itemService.findItemPessimisticLock(itemId); // ←
checkStock(item);
Purchase purchase = Purchase.builder().item(item).user(user).build();
purchaseRepository.save(purchase);
item.sellOne();
}
비관적 락 적용 후 테스트 진행
락 적용 후, 데이터의 정확성이 지켜지고 있는지 테스트해보았다. (마찬가지로 테스트는 JUnit으로, 위와 동일한 코드로 진행했다.)
➡️ 테스트 조건 1: 사용자 1,000명이 100개의 상품에 대해 동시에 구매 요청

➡️ 테스트 조건 2: 사용자 5,000명이 100개의 상품에 대해 동시에 구매 요청

락이 제대로 적용되어 테스트 조건 1, 2를 모두 통과했다. 하지만, nGrinder를 통해 요청이 단 시간에 폭발적으로 발생하는 경우에는 비관적 락의 한계점이 뚜렷하게 나타났다.
한계
nGrinder에서 PK Id 값을 사용하여 상품 상세 페이지 조회 테스트를 실행했다. 15분 간 1,000명의 vUser가 상품을 구매하는 POST 요청에 대한 부하 테스트 수행했을 때, 약 10 ~ 20% 정도의 에러율을 보였다.
nGrinder를 통한 테스트 진행
테스트 케이스
💼 PK Id 값을 사용하여 상품 상세 페이지 조회
- HTTP POST 요청
- AWS EC2 환경에서 테스트 (원격)
- timeout 5초 설정(5초 초과 시 error처리)
1. 상품 id 값 고정하여 구매 테스트
- 한 페이지에 트래픽이 몰리는 것을 상정하여 스크립트를 작성
2. 상품 id 값 랜덤으로 지정하여 구매 테스트
- 여러 페이지에서 구매가 이루어지는 일반적인 이커머스 사이트 상황을 상정하여 스크립트를 작성
테스트 실행 환경
| 원격 서버 (배포 서버) | nGrinder 서버 | |
|---|---|---|
| 인스턴스 타입 | ec2.t3a.xlarge | ec2.m5zn.large |
| CPU | 4 vCPUs | 2 vCPUs |
| RAM | 16GB | 8GB |
| Storage | 8 GiB, EBS, 범용 SSD(gp3) | 8 GiB, EBS, 범용 SSD(gp3) |
| RDS(DB) | db.t3.xlarge (4 vCPUs, 16 GiB Mems) | x |
Test Configuration(nGrinder)
| Settings | |
|---|---|
| Agent 수 | 1 |
| Vuser per agent | 1,000 |
| - Processes | 10 |
| - Threads | 100 |
| Duration (HH:MM:SS) | 00:15:00 |
| Ramp-Up | X (설정 안 함) |
➡️ 테스트 케이스 1: 상품 id 값 ‘고정’
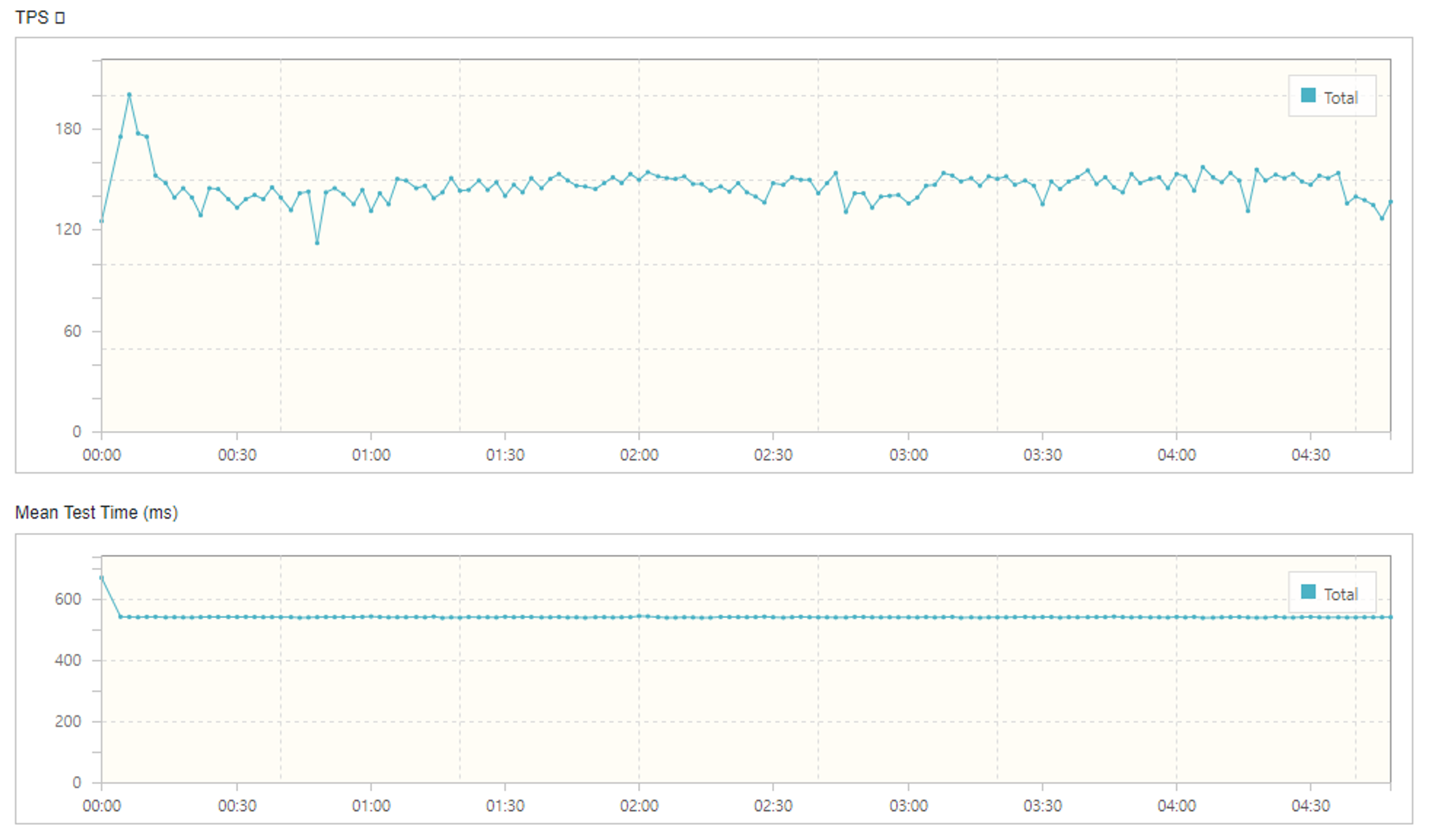
| Results | |
|---|---|
| Executed Tests | 53,225 |
| Errors | 11,236 |
| Error Rate | 21.1% |
| TPS | 145.8 |
| MTT (ms) | 540.44 |
- TPS: 초당 평균 145.8건의 트랜잭션 처리
- MTT: 요청에 대한 응답시간 540.44ms
- 에러율: 21.1%
➡️ 테스트 케이스 2: 상품 id 값 ‘랜덤 지정’
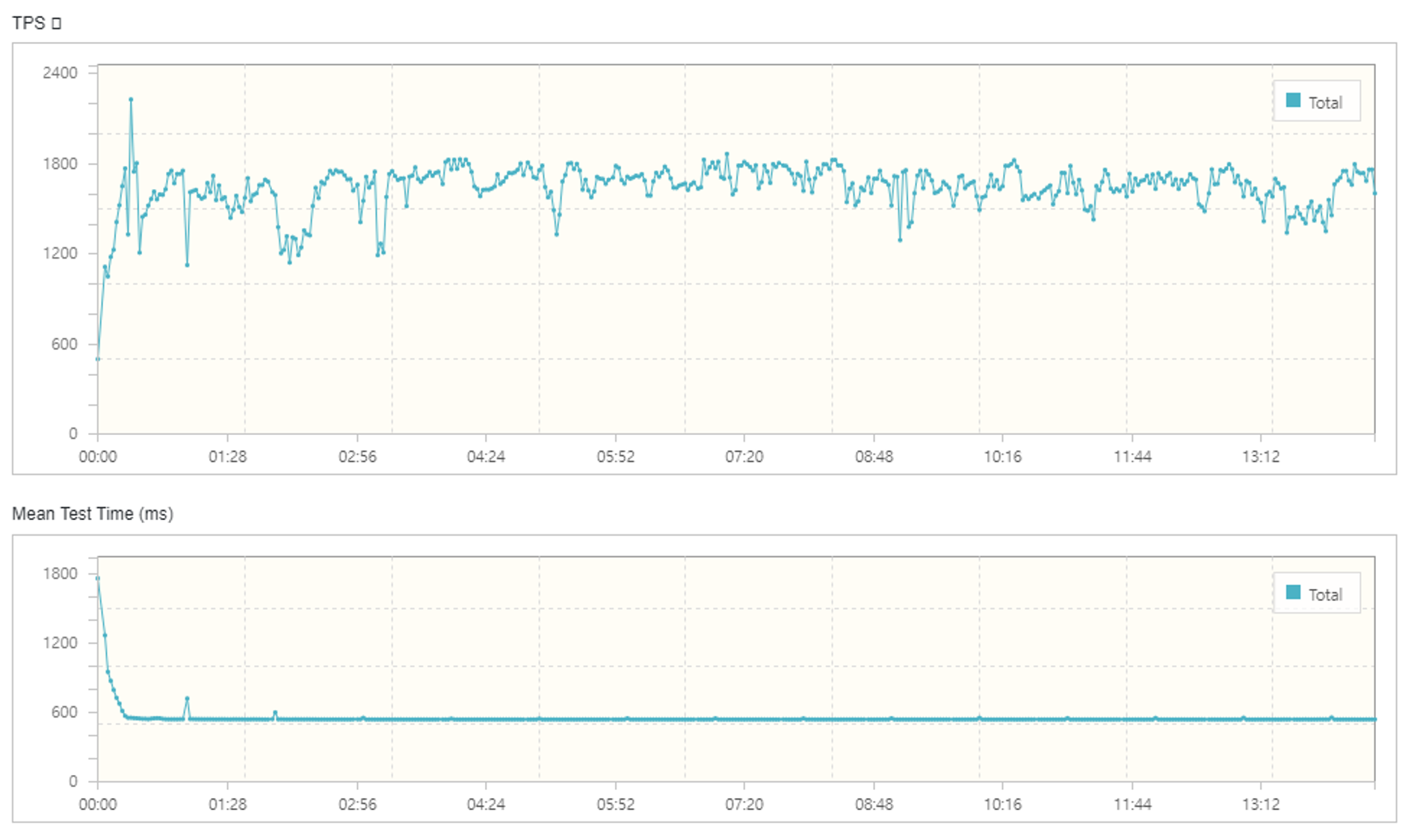
| Results | |
|---|---|
| Executed Tests | 1,595,639 |
| Errors | 169,768 |
| Error Rate | 10.6% |
| TPS | 1,638.4 |
| MTT (ms) | 545.46 |
- TPS: 초당 평균 1,638.4건의 트랜잭션 처리
- MTT: 요청에 대한 응답시간 545.46ms
- 에러율: 10.6%
로그를 확인한 결과, 실제 발생한 오류는 CONNECTION TIMEOUT의 비중이 가장 높았다. 동시성 제어를 위해 사용한 ‘비관적 락’으로 인해 DB에 락(Lock)이 걸려있는 것이 원인이었다. 락으로 인해 처리시간이 지체되는데, 트래픽까지 다량으로 몰리는 바람에 스레드는 TIMEOUT 제한(= 5초)까지 일이 처리되지 못했거나, 응답을 받지 못한 것이다.
상품 id 값 ‘고정’과 ‘랜덤’의 결과가 다르게 나온 것도 이 이유이다. 해당하는 아이템 row마다 락을 걸어주기 때문이다. ‘고정’의 경우는 다량의 트래픽이 몰려서 지체될 확률이 높지만, ‘랜덤’의 경우는 다량의 트래픽이 몰릴 확률이 굉장히 낮다.
해결 방안 (개선점)
특히 ‘고정’ 테스트 케이스에서 오류율이 높고, TPS 처리량이 낮았던 문제를 개선하기 위하여, 다음과 같은 방안을 생각해보았다.
1. 대기열 시스템을 생성한다:
대기열을 생성하여 의도적으로 요청 처리 속도를 늦추는 방식이다. 현재도 단 시간에 사용자가 다량 몰리는 티켓팅 사이트 등에서 많이 사용하고 있다.
2. 트래픽이 몰릴 상품의 정보를 미리 캐싱하고, 캐싱된 상품 테이블에서 정보를 받아오도록 한다:
비관적 락 사용 시, 트랜잭션의 대기 시간 증가로 인해 Timeout 오류가 발생한다. 이 점을 보완하기 위해, In-memory DB 등을 사용하여 상품의 정보를 미리 메모리에 캐싱해두고, 캐싱된 테이블에서 트랜잭션을 처리하는 방법이다. 메모리는 디스크보다 I/O 속도가 수백배 빠르기 때문에, 문제를 효과적으로 개선할 수 있을 것이다.
-
트랜잭션: Transaction; 데이터베이스의 상태를 변화시키기 해서 수행하는 작업의 단위. ↩
댓글남기기